- 实验任务:使用TensorFlow实现CAPTCHA注册码的识别
- 基本思路:采用 Captcha 库生成验证码,将验证码识别问题转化为分类问题,采用 CNN 网络模型进行训练,最终实现对验证码的破解。
- 实验步骤:获取验证码训练集 → 构建卷积神经网络和全连接神经网络 → 定义损失函数以及优化方式 → 进行训练并保存训练结果。
获取验证码训练集
使用captcha库来生成验证码,captcha库可以使用anaconda很轻松下载,captcha库不仅可以用于生成图片验证码,还可以用来生成语音验证码。
- 我们将ImageCaptcha类实例化为image对象,构造函数的参数里指定宽度和高度。
image = ImageCaptcha(width=self.width, height=self.height)
存储训练数据。
我们创建两个矩阵X和Y用以表示训练集的输入部分和输出部分,也就是验证码的图片数据存储以及验证码上所写的内容存储。
1
2X = np.zeros([batch_size, self.height, self.width, 1])
Y = np.zeros([batch_size, self.char_num, self.classes])这两个矩阵的第一维参数都是batch_size,表示这一组训练集的个数。
X的第二和第三位参数分别表示验证码的高度和宽度,最后一个参数表示这是1通道的黑白图片。
Y的第二位参数表示此验证码上写了几个字符,第三位参数表示每个字符共有多少种选择,这是一条长为self.classes的向量,以独热编码的形式记录信息。
生成验证码
1
2
3
4
5
6
7
8
9
10while True:
for i in range(batch_size):
captcha_str = ''.join(random.sample(self.characters, self.char_num))
img = image.generate_image(captcha_str).convert('L')
img = np.array(img.getdata())
X[i] = np.reshape(img, [self.height, self.width, 1]) / 255.0
for j, ch in enumerate(captcha_str):
Y[i, j, self.characters.find(ch)] = 1
Y = np.reshape(Y, (batch_size, self.char_num * self.classes))
yield X, Y首先,这个总体的无限循环是一个训练集的生成器,执行此代码后,会在最后的yield语句返回训练集X和Y,然后循环结束。下次再想生成验证码训练集时,会从yield语句(最后一句)开始,回到开头再执行一次循环。
这样的好处是,以前都是将所有的训练数据全部准备好,然后手动分出很多batch,一个一个的训练,这样的话要求把所有的训练数据全部装入内存,很浪费内存空间。而使用这种生成器语句,如果我训练哪一个batch的数据,就立即生成数据并装入内存,用完再撤出内存,紧接着训练下一个batch的数据时,再立即生成然后将其装入内存。分批装入内存,节省了大量的内存空间。
1
random.sample(self.characters, self.char_num)
此代码生成一个验证码字符串的随机变量,self.characters为62位的字符串(0~9A~Za~z),self.char_num=4(生成4个字符)。
1
img = image.generate_image(captcha_str).convert('L')
这句代码使用的是ImageCaptcha类的内置方法,将字符串变为图片。convert(‘L’):表示生成的是灰度图片,就是通道数为1的黑白图片。
1
X[i] = np.reshape(img, [self.height, self.width, 1]) / 255.0
每个像素值都要除以255,这是为了归一化处理,因为灰度的范围是0~255,这里除以255就让每个像素的值在0~1之间,目的是为了加快收敛速度。
1
2for j, ch in enumerate(captcha_str):
Y[i, j, self.characters.find(ch)] = 1这里用以生成对应的测试集Y,j和ch用以遍历刚刚生成的随机字符串,j记录index(0~3,表示第几个字符),ch记录字符串中的字符。找到Y的第i条数据中的第j个字符,然后把62长度的向量和ch相关的那个置为1。
构建卷积神经网络和全连接神经网络
conv2D
1
2def conv2d(self, x, W):
return tf.nn.conv2d(x, W, strides=[1, 1, 1, 1], padding='SAME')这是2维卷积函数。x表示传入的待处理图片,W表示卷积核,strides=[1, 1, 1, 1],其中第二个和第三个1分别表示x方向步长和y方向步长,padding=’SAME’表示边界处理策略设为’SAME’,这样卷积处理完图片大小不变。
max_pool_2x2
1
2def max_pool_2x2(self, x):
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME')这是2x2最大值池化函数。x表示待被池化处理的图片,ksize=[1, 2, 2, 1],其中第二个和第三个2分别表示池化窗口高度和池化窗口宽度,strides和padding意义同上。
weight_variable
1
2
3def weight_variable(self, shape):
initial = tf.truncated_normal(shape, stddev=0.1)
return tf.Variable(initial)这就是一个很有意思的函数了,用这个函数的目的是从截断的正态分布中输出随机值。听着名字就不知道是个什么鬼,我们先看看正太分布的一个性质:
在正态分布的曲线中,横轴区间(μ-σ,μ+σ)内的面积为68.268949%。
横轴区间(μ-2σ,μ+2σ)内的面积为95.449974%。
横轴区间(μ-3σ,μ+3σ)内的面积为99.730020%。
X落在(μ-3σ,μ+3σ)以外的概率小于千分之三,在实际问题中常认为相应的事件是不会发生的,基本上可以把区间(μ-3σ,μ+3σ)看作是随机变量X实际可能的取值区间,这称之为正态分布的“3σ”原则。
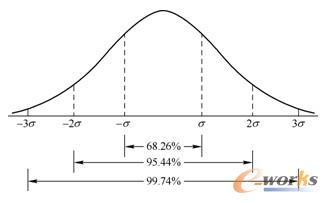
而从截断的正态分布中输出随机值的意思就是,同样也是随机生成的值,但是生成的值必须服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择。换句话说,就是如果随机生成的值如果落在了(μ-2σ,μ+2σ)之外,就重新生成值,这样就保证了随机生成的值都在均值附近。
扯了这么多,其实就是随机生成一组数,要求不要离中心点μ太远。
bias_variable
1
2
3def bias_variable(self, shape):
initial = tf.constant(0.1, shape=shape)
return tf.Variable(initial)生成一组全部都是0.1的常量数,没啥好说的。
构建第一层卷积神经网络
1
2
3
4
5
6
7w_conv1 = self.weight_variable([5, 5, 1, 32])
b_conv1 = self.bias_variable([32])
h_conv1 = tf.nn.relu(tf.nn.bias_add(self.conv2d(x_images, w_conv1), b_conv1))
h_pool1 = self.max_pool_2x2(h_conv1)
h_dropout1 = tf.nn.dropout(h_pool1, keep_prob)
conv_width = math.ceil(self.width / 2)
conv_height = math.ceil(self.height / 2)w_conv1是卷积核,可以理解为一共有32个卷积核,每个卷积核的尺寸是(5, 5, 1),即长度和宽度都是5,通道是1。每个卷积核对图片处理完就会产生一张特征图,32个卷积核对图片处理完后就会产生32个特征图,将这些特征图叠加排列,那么原本通道数为1的图片现在通道数变为图片的个数,也就是32。图片的尺寸变化为(?, 60, 160, 1) –> (?, 60, 160, 32)。
随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。图片的尺寸变化为(?, 60, 160, 32) → (?, 30, 80, 32)。
随后又进行了一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
构建第二层卷积神经网络
1
2
3
4
5
6
7w_conv2 = self.weight_variable([5, 5, 32, 64])
b_conv2 = self.bias_variable([64])
h_conv2 = tf.nn.relu(tf.nn.bias_add(self.conv2d(h_dropout1, w_conv2), b_conv2))
h_pool2 = self.max_pool_2x2(h_conv2)
h_dropout2 = tf.nn.dropout(h_pool2, keep_prob)
conv_width = math.ceil(conv_width / 2)
conv_height = math.ceil(conv_height / 2)w_conv2是第二层卷积神经网络的卷积核,共有64个,每个卷积核的尺寸是(5, 5, 32),处理之后图片的尺寸变化为(?, 30, 80, 32) → (?, 30, 80, 64)。
随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。图片的尺寸变化为(?, 30, 80, 64) → (?, 15, 40, 64)。
再进行一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
构建第三层卷积神经网络
1
2
3
4
5
6
7w_conv3 = self.weight_variable([5, 5, 64, 64])
b_conv3 = self.bias_variable([64])
h_conv3 = tf.nn.relu(tf.nn.bias_add(self.conv2d(h_dropout2, w_conv3), b_conv3))
h_pool3 = self.max_pool_2x2(h_conv3)
h_dropout3 = tf.nn.dropout(h_pool3, keep_prob)
conv_width = math.ceil(conv_width / 2)
conv_height = math.ceil(conv_height / 2)w_conv3是第三层卷积神经网络的卷积核,共有64个,每个卷积核的尺寸是(5, 5, 64),处理之后图片的尺寸变化为(?, 15, 40, 64) → (?, 15, 40, 64)。
随后又对图片进行一次池化处理,池化窗口为2×2,所以图片的长度和宽度都会变为原来的一半。图片的尺寸变化为(?, 15, 40, 64) → (?, 8, 20, 64),这里的15 / 2 = 8,是因为边界策略为SAME,那么遇到剩下还有不足4个像素的时候同样采取一次最大值池化处理。
再进行一次dropout以防止过拟合,同时也是为了加大个别神经元的训练强度。
构建第一层全连接神经网络
1
2
3
4
5
6
7conv_width = int(conv_width)
conv_height = int(conv_height)
w_fc1 = self.weight_variable([64 * conv_width * conv_height, 1024])
b_fc1 = self.bias_variable([1024])
h_dropout3_flat = tf.reshape(h_dropout3, [-1, 64 * conv_width * conv_height])
h_fc1 = tf.nn.relu(tf.nn.bias_add(tf.matmul(h_dropout3_flat, w_fc1), b_fc1))
h_fc1_drop = tf.nn.dropout(h_fc1, keep_prob)这里就把刚刚卷积神经网络的输出作为传统神经网络的输入了,w_fc1(10240, 1024)和b_fc1(1024)分别是这一层神经网络的参数以及bias。上面代码第五行将卷积神经网络的输出数据由(?, 8, 20, 64)转为了(?, 64 20 8),可以很明显感觉出来把所有的数据拉成了一条一维向量,然后经过矩阵处理,这里的数据变为了(1024, 1)的形状。
构建第二层全连接神经网络
1
2
3w_fc2 = self.weight_variable([1024, self.char_num * self.classes])
b_fc2 = self.bias_variable([self.char_num * self.classes])
y_conv = tf.add(tf.matmul(h_fc1_drop, w_fc2), b_fc2)再连接一次神经网络,这次不再需要添加激励函数了ReLu了,因为已经到达输出层,线性相加后直接输出就可以了,结果保存在y_conv变量里,最后将y_conv返回给调用函数。
1
y_conv = model.create_model(x, keep_prob)
这是外层函数调用model后所得到的训练结果。
定义损失函数以及优化方式
1 | cross_entropy = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(labels=y_, logits=y_conv)) |
由于识别验证码本质上是对验证码中的信息进行分类,所以我们这里使用cross_entropy的方法来衡量损失。
1 | train_step = tf.train.AdamOptimizer(1e-4).minimize(cross_entropy) |
优化方式选择的是AdamOptimizer,学习率设置比较小,为1e-4,防止学习的太快而训练不好。
进行训练并保存训练结果
1 | saver = tf.train.Saver() |
从第二行开始进入训练部分,首先我们需要初始化变量,然后进入一个循环,直到训练的准确度高于99%才会停止训练,否则会一直训练下去。
1 | batch_x, batch_y = next(captcha.gen_captcha(64)) |
用于生成训练集,每次生成64条训练数据,输入部分保存在batch_x里,输出部分保存在batch_y里,每次循环到这里就会再次读入64条训练数据。
1 | _, loss = sess.run([train_step, cross_entropy], feed_dict={x: batch_x, y_: batch_y, keep_prob: 0.75}) |
开始训练,loss记录损失,_变量不记录任何东西,我debug下来每次_里面都是空,可能只是为了语法的需要,这里必须有个变量接受点什么。
1 | if step % 100 == 0: |
每训练一百次,就会进行一次Test。具体操作是,生成100条测试数据,和之前生成训练数据是一个方法,然后直接进行测试,如果准确度高于99%那么就停止训练,把训练好的模型放在”capcha_model.ckpt”这个文件里面,可以供以后使用。如果没有达到99%的准确度就继续训练。
六、完整代码
train_captcha.py
训练的主代码
1 | import tensorflow as tf |
generate_captcha.py
生成验证码的类
1 | from captcha.image import ImageCaptcha |
captcha_model.py
训练模型的类
1 | import tensorflow as tf |
predict_captcha.py
我们把训练好的模型保存起来,之后可以使用此代码去识别任意的验证码,只要图片输入的要求符合高60宽160且1通道黑白图片即可。这个类上面我没讲解,我也没机会试,因为训练时间太久了我还没训出来呢,据说GPU训练需要4~5个小时,CPU训练的话需要20小时,大家训练好了可以拿去试试。
1 | from PIL import Image |