分布式第一次实验,怎么坑这么多!🤯
首先
你需要开3台虚拟机,一台作为master主节点,两个作为slave从节点,分别叫做slave1和slave2。
VMware虚拟机桥接模式设置
参考这个文章,(没用过VMware23333)
Parallels虚拟机桥接模式设置
参考这个文章,IP的起始地址设为192.168.1.11,结束地址设为192.168.1.31
hostname的配置操作
修改hosts文件,如下(master节点、slave1节点、slave2节点都做):
1
2sudo su root # 若当前不是root就进入root账户
gedit /etc/hosts修改内容如下:
1
2
3192.168.1.11 master
192.168.1.12 slave1
192.168.1.13 slave2修改hostname
1
2master节点上修改为master,slave1节点和slave2节点上分别修改为slave1、slave2
hostname master/slave1/slave2这样不能彻底修改hostname(主机名),重启后还会还原到默认的Ubuntu,要彻底修改要修改/etc/hostname,namenode和datanode各自修改为自己的hostname
直接用编辑器打开/etc/hostname这个文件,把原来的名称删掉,不要用#注释,直接删掉,因为#没用,修改内容:
1
2master节点上修改为master,slave1节点和slave2节点上分别修改为slave1、slave2
master/slave1/slave2退出shell客户端,重新进入,并且换成root操作(这是教程上的一步,没看懂这是什么操作)
1
2exit
sudo su root这些工作都做好了,互相ping一下看看能不能ping通,ping 节点名称
1
ping master/slave1/slave2
安装jdk(所有节点都做)
前往oracle Java官网下载JDK
确保当前是系统账户
1
sudo su root
解压缩到指定目录(以jdk-8u201-linux-x64.tar.gz为例)
创建目录:
1
mkdir /usr/lib/jvm
解压缩到该目录:
1
tar -zxvf jdk-8u201-linux-x64.tar.gz -C /usr/lib/jvm
修改环境变量,如果提示没有装vim就使用
apt install vim装一个:1
vim ~/.bashrc
在文件末尾追加下面内容:
1
2
3
4
5set oracle jdk environment
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_201 # 这里要注意目录要换成自己解压的jdk 目录
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH使环境变量马上生效:
1
source ~/.bashrc
系统注册此jdk
1
update-alternatives --install /usr/bin/java java /usr/lib/jvm/jdk1.8.0_201/bin/java 300
查看java版本,看看是否安装成功:
1
java -version
SSH无密码验证配置
在master节点上:
先安装ssh
1
sudo apt-get install ssh
先创建本地公钥:
1
2
3
4mkdir ~/.ssh
cd ~/.ssh
rm ./id_rsa* # 删除之前生成的公匙(如果有)
ssh-keygen -t rsa # 一直按回车就可以让 Master 节点需能无密码 SSH 本机,在 Master 节点上执行:
1
cat ./id_rsa.pub >> ./authorized_keys
完成后可执行
ssh Master验证一下(可能需要输入 yes,成功后执行exit返回原来的终端)。接着在 master 节点将上公匙传输到 slave1 节点和slave2节点:1
2scp ./id_rsa.pub parallels@slave1:/home/parallels/ # 向slave1节点传
scp ./id_rsa.pub parallels@slave2:/home/parallels/ # 向slave2节点传
在slave1节点上(slave2同理):
将 ssh 公匙加入授权:
1
2mkdir /root/.ssh # 如果不存在该文件夹需先创建,若已存在则忽略
cat /home/parallels/id_rsa.pub >> /root/.ssh/authorized_keys
在master节点上测试:
执行ssh slave1,会有这样的结果:
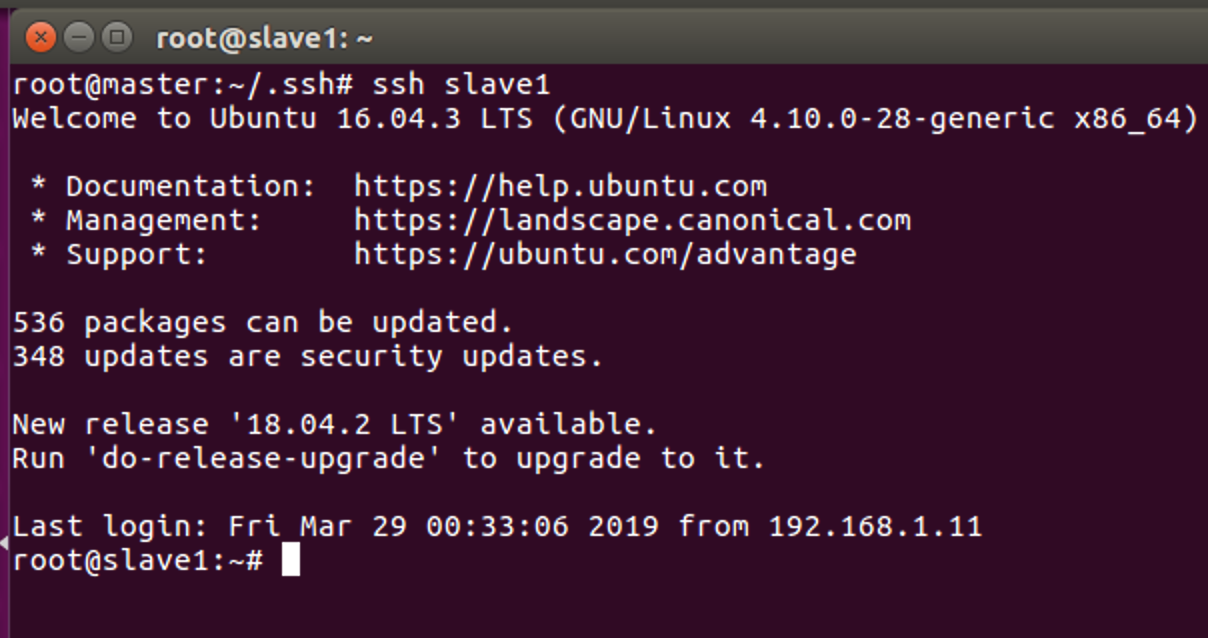
那么说明成功了,再执行ssh slave2看看。
关闭防火墙
所有节点上,执行ufw disable就好。
安装Hadoop
在master节点上:
[注]全程在root账户下运行
1 | sudo su root # 若当前不是root就进入root账户 |
到Hadoop官网下载binary的hadoop,我下载的是hadoop-2.8.5.tar.gz文件
在/usr/local目录下建立hadoop目录
1
mkdir /usr/local/hadoop
把hadoop-2.8.5.tar.gz拷贝到/usr/local/hadoop目录下,然后解压,这里的
<path>写自己的下载位置1
2
3
4cp <path>/hadoop-2.8.5.tar.gz /usr/local/hadoop
cd /usr/local/hadoop
tar –zxvf hadoop-2.8.5.tar.gz
cd hadoop-2.8.5在/usr/local/hadoop目录下新建tmp文件夹和hdfs文件夹
1
2
3cd /usr/local/hadoop
mkdir tmp
mkdir hdfs编辑(可用
vim hadoop-env.sh也可双击打开编辑)hadoop-2.8.5/etc/hadoop/hadoop-env.sh文件,把JAVA_HOME设置成Java安装根路径,如下:1
2cd /usr/local/hadoop/hadoop-2.8.5/etc/hadoop
export JAVA_HOME=/usr/lib/jvm/jdk1.8.0_201新建slaves文件
1
vi slaves
添加这两条
1
2slave1
slave2编辑master文件,全文改为
master修改hadoop-2.8.5/etc/hadoop/core-site.xml文件(我在文件系统里使用的sublime修改的文件,也可以直接双击使用gedit打开)
1
2
3
4
5
6
7
8
9
10
11<configuration>
<property>
<name>fs.defaultFS</name>
<value>hdfs://master:9000</value>
</property>
<property>
<name>hadoop.tmp.dir</name>
<value>file:/usr/local/hadoop/tmp</value>
<description>Abase for other temporary directories.</description>
</property>
</configuration>修改hadoop-2.8.5/etc/hadoop/hdfs-site.xml文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18<configuration>
<property>
<name>dfs.namenode.secondary.http-address</name>
<value>master:50090</value>
</property>
<property>
<name>dfs.replication</name>
<value>3</value>
</property>
<property>
<name>dfs.namenode.name.dir</name>
<value>file:/usr/local/hadoop/hdfs/name</value>
</property>
<property>
<name>dfs.datanode.data.dir</name>
<value>file:/usr/local/hadoop/hdfs/data</value>
</property>
</configuration>修改hadoop-2.8.5/etc/hadoop/mapred-site.xml文件(可能需要先重命名,默认文件名为 mapred-site.xml.template)
1
2
3
4
5
6
7
8
9
10
11
12
13
14<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
<property>
<name>mapreduce.jobhistory.address</name>
<value>master:10020</value>
</property>
<property>
<name>mapreduce.jobhistory.webapp.address</name>
<value>master:19888</value>
</property>
</configuration>修改hadoop-2.8.5/etc/hadoop/yarn-site.xml文件
1
2
3
4
5
6
7
8
9
10<configuration>
<property>
<name>yarn.resourcemanager.hostname</name>
<value>master</value>
</property>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>将配置好的文件复制到各个slave节点上:
1
2
3
4
5
6cd /usr/local
sudo rm -r ./hadoop/tmp # 删除 Hadoop 临时文件
tar -zcf ~/hadoop.master.tar.gz ./hadoop # 先压缩再复制
cd ~
scp ./hadoop.master.tar.gz slave1:/home/parallels
scp ./hadoop.master.tar.gz slave2:/home/parallels
在slave1节点上:
解压文件,并修改owner
1
2
3sudo su root # 若当前不是root就进入root账户
rm -r /usr/local/hadoop # 删掉旧的(如果存在)
tar -zxf /home/parallels/hadoop.master.tar.gz -C /usr/local
回到master节点
将bin目录和sbin目录里的命令配入环境变量
1
vim ~/.bashrc
按下
i,在最后添加一行:1
export PATH=$PATH:/usr/local/hadoop/hadoop-2.8.5/sbin:/usr/local/hadoop/hadoop-2.8.5/bin
然后按下
esc,输入:wq写入文件。使环境变量马上生效:
1
source ~/.bashrc
在 Master 节点执行 NameNode 的格式化
1
hadoop namenode -format
接着可以启动 hadoop 了,启动需要在 Master 节点的sbin文件夹中进行:
1
2start-all.sh
mr-jobhistory-daemon.sh start historyserver
通过命令
jps可以查看各个节点所启动的进程。正确的话,在 Master 节点上可以看到 NameNode、ResourceManager、SecondrryNameNode、JobHistoryServer 进程。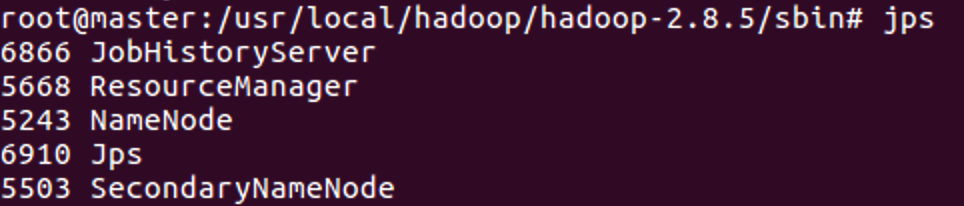
分别进入slave1节点和slave2节点,使用
jps命令查看运行情况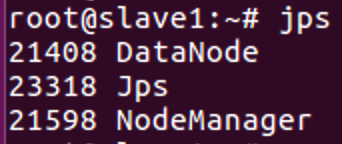
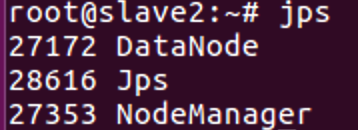
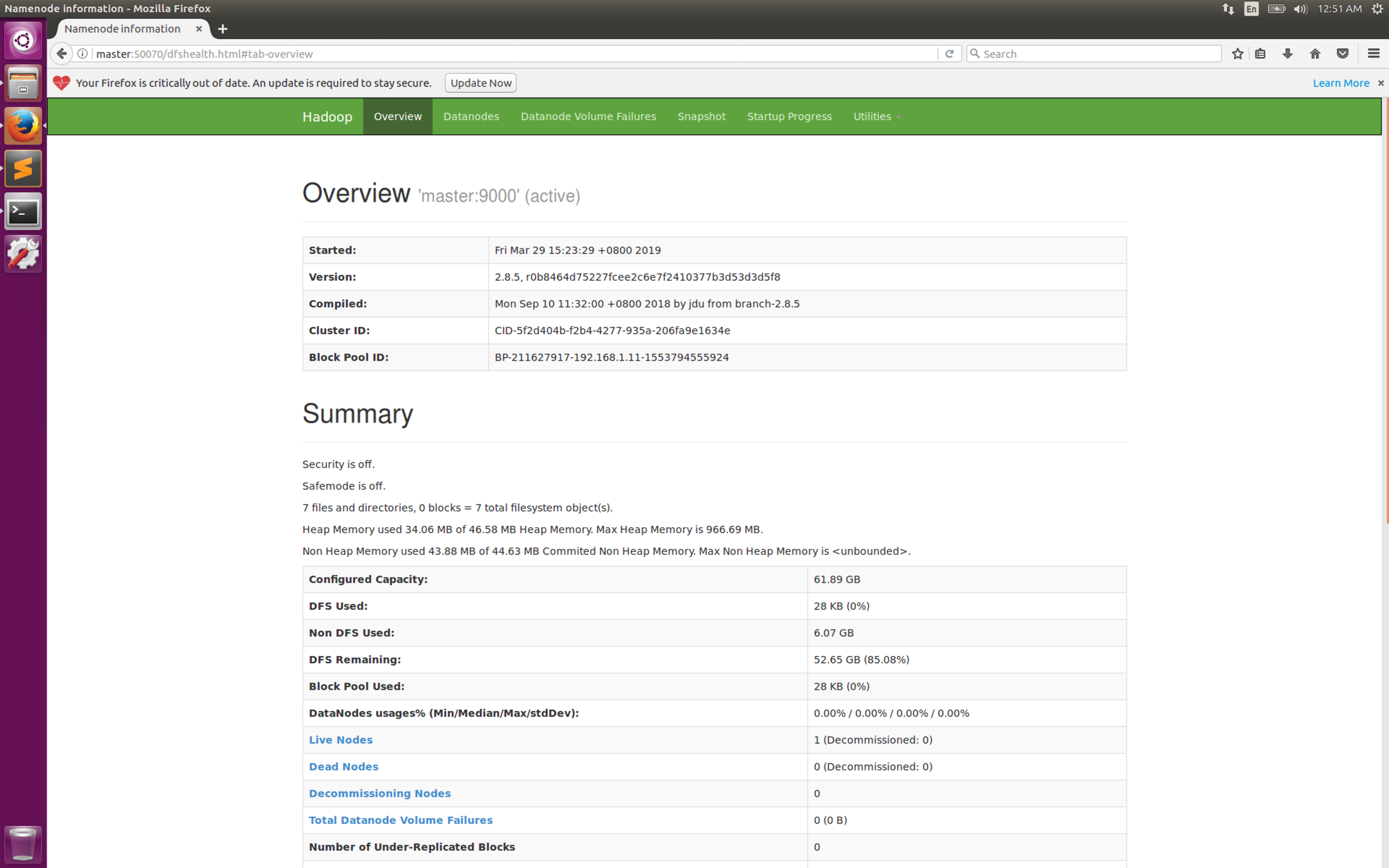
在namenode上查看集群状态
1
hadoop dfsadmin -report
此时可以通过在浏览器中打开http://master:50070查看。
结束语
如各位同学发现问题欢迎评论指正,评论功能终于打开了233333!
致谢
感谢苏璐岩、wanghj、汪宇同学为本文指正错误!